K-means Clustering
✕K-means Clustering Concept
- Partition data into K clusters based on feature similarity.
- Use Case:
Customer segmentation,Recommendation Systemsetc. - Initialize K cluster centroids randomly.
- Assign each data point to the nearest centroid to form clusters.
- Update centroids by calculating the mean of points in each cluster.
- Repeat 2nd & 3rd steps 2 and 3 until convergence.
Algorithm Steps
K-means Concept Visually: Step 1

K-means Concept Visually: Step 2
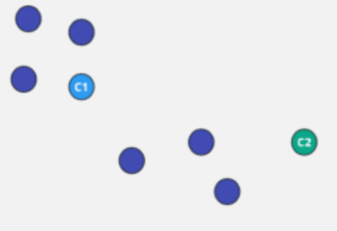
K-means Concept Visually: Step 3
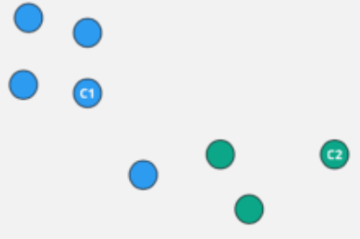
K-means Concept Visually: Step 4

K-means Concept Visually: Step 5

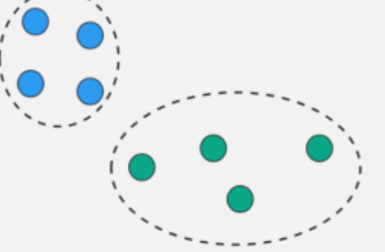
K-means Concept Visually: Step 6

K-means Concept Visually: Step 7

K-means Concept Visually: Step 8
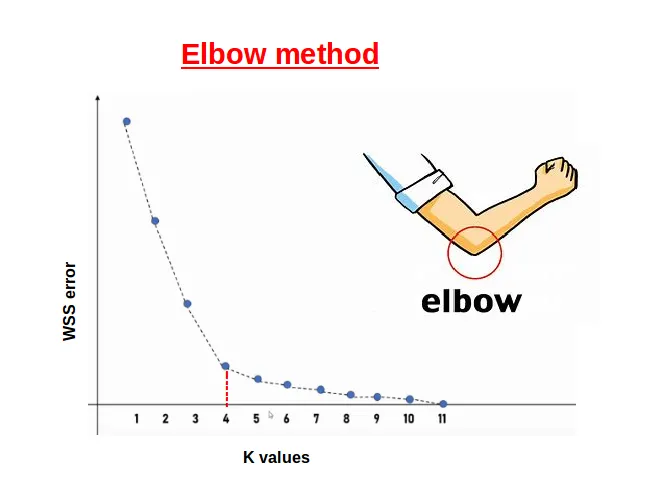
Choosing K with Elbow Method
- Run K-means for a range of K values (e.g. 1 to 10).
- Plot
inertia/wcss(sum of squared distances to its centroid) vs K. - Look for "elbow" point where inertia reduction slows down.
- Elbow point suggests optimal K balancing fit and complexity.