
Linear Regression
✕Linear Regression Introduction
- Predicts continuous target variable based on linear relationship with features.
- Model is represented as
y = β0 + β1x1 + β2x2 + ... + βnxn. - Coefficients (β) are estimated using least squares method to minimize the sum of squared residuals.
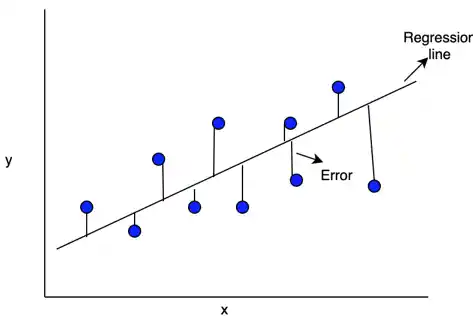
Deriving Coefficients in Linear Regression (2D)
- For simple linear regression with one feature (x) and one target variable (y). The model is
y = β0 + β1x. - Assume we have n data points (x1, y1), (x2, y2), ..., (xn, yn).
- The goal is to find β0 and β1 that minimize the sum of squared residuals.
- For x1, the predicted value by model is
y_pred = β0 + β1x1. - The residual for x1 is
e1 = y1 - y_pred=y1 - (β0 + β1x1)=y1 - β0 - β1x1. - The sum of squared residuals is
RSS = Σ(ei²)=Σ(yi - β0 - β1xi)². - To minimize RSS, we take partial derivatives w.r.t
β0andβ1and set them to zero. ∂RSS/∂β0 = 2*Σ(yi - β0 - β1xi) * (-1) = 0 or Σ(yi - β0 - β1xi) = 0 or Σyi - n*β0 - β1Σxi = 0 or nβ0 = (Σyi - β1Σxi) or β0 = (Σyi - β1Σxi) / n => β0 = Ȳ - β1X̄∂RSS/∂β1 = 2*Σ(yi - β0 - β1xi) * (-xi) = 0 or Σ(yi - β0 - β1xi) * xi = 0 or Σ(xi*yi) - β0Σxi - β1Σ(xi)² = 0 => β1Σ(xi)² = Σ(xi*yi) - β0Σxi- On solving these two equations, we get:
β1 = COV(X, Y) / VAR(X) β0 = Ȳ - β1X̄
Partial Derivatives w.r.t. β0:
Partial Derivatives w.r.t. β1:
Hyperparameters in Linear Regression
Linear Regression Hyperparameters and their Effects:
| Hyperparameter | Description | Effect on Model |
|---|---|---|
| fit_intercept | Whether to calculate the intercept for this model. | True => model includes intercept (β0), False => model does not include intercept. |
| positive | When set to True, forces the coefficients to be positive. | True => coefficients constrained to be positive (better interpretability), False => coefficients can take any value (allows for more flexibility). |
Linear Regression has no hyperparameters to tune, but regularization techniques can be applied to prevent overfitting.
Regularization in Linear Regression
- Regularization adds a penalty term to the loss function to prevent overfitting.
Regularization Techniques for Linear Regression:
| Technique | Description | Effect on Model |
|---|---|---|
| Lasso Regression (L1) | Adds a penalty equal to the absolute value of the magnitude of coefficients. | Encourages sparsity, can perform feature selection by shrinking some coefficients to zero. |
| Ridge Regression (L2) | Adds a penalty equal to the square of the magnitude of coefficients. | Encourages smaller coefficients, reduces model complexity, can handle multicollinearity. |
| Elastic Net | Combines L1 and L2 penalties. | Balances between Ridge and Lasso, can handle correlated features and perform feature selection. |
Common regularization techniques for linear regression include Ridge (L2), Lasso (L1), and Elastic Net.